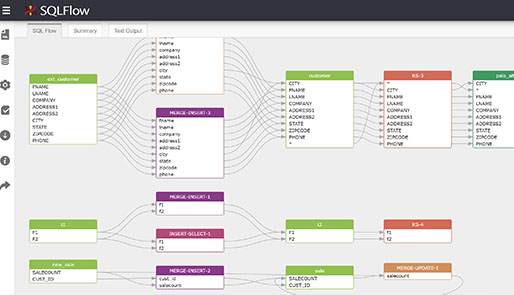
Wat is Data Lineage?
Data lineage (ook wel dataspoorbeheer genoemd) is het proces van het traceren en documenteren van de levenscyclus van data - van de oorspronkelijke bron tot de uiteindelijke bestemming. Het biedt een volledig overzicht van hoe data door een organisatie stroomt, welke transformaties het ondergaat en wie het gebruikt.
Waarom is Data Lineage Belangrijk?
In een tijd waarin data-driven besluitvorming cruciaal is voor succes, biedt data lineage verschillende belangrijke voordelen:
Datakwaliteit
Identificeer snel de bron van dataproblemen en los ze op bij de oorsprong.
Compliance
Voldoe aan regelgeving zoals GDPR, SOX en BCBS 239 door volledige datatransparantie.
Impactanalyse
Bepaal welke systemen en rapporten worden beïnvloed door wijzigingen in databronnen.
Vertrouwen in data
Stakeholders hebben meer vertrouwen in data wanneer ze de herkomst en transformaties begrijpen.
Soorten Data Lineage
| Type | Beschrijving | Gebruik |
|---|---|---|
| Business Lineage | Hoog niveau overzicht voor business gebruikers | Communicatie, documentatie |
| Technische Lineage | Gedetailleerd spoor van databases, tabellen en kolommen | Impactanalyse, troubleshooting |
| Operational Lineage | Focus op ETL/ELT processen en data pipelines | Procesoptimalisatie, monitoring |
| End-to-End Lineage | Compleet spoor van bron tot eindgebruiker | Compliance, datagovernance |
Hoe Werkt Data Lineage in de Praktijk?
Een typisch data lineage proces volgt deze stappen:
Databronnen identificeren
Vaststellen van alle bronnen waar data vandaan komt (databases, API's, bestanden)
Extractie & transformatie
Documenteren van ETL/ELT processen en datatransformaties
Dataopslag
In kaart brengen van datawarehouses, datalakes en andere opslagsystemen
Consumptie
Documenteren van rapporten, dashboards en applicaties die data gebruiken
Voordelen vs Uitdagingen
Voordelen van Data Lineage
- Verbeterde datakwaliteit en betrouwbaarheid
- Snellere troubleshooting en root cause analysis
- Eenvoudigere compliance en auditing
- Betere samenwerking tussen IT en business
- Minder risico bij systeemwijzigingen
Uitdagingen bij Implementatie
- Complexiteit in grote, gefragmenteerde systemen
- Hoge initiële investering in tools en processen
- Weerstand tegen verandering in organisatiecultuur
- Onderhoud van lineage bij frequente systeemwijzigingen
- Integratie met bestaande tools en platformen
Praktijkvoorbeelden van Data Lineage
GDPR Compliance
Een financiële instelling gebruikt data lineage om persoonlijke gegevens te traceren door hun systemen, waardoor ze snel kunnen voldoen aan verzoeken om gegevens te wissen (right to be forgotten).
Foutdetectie in Rapporten
Een retailer identificeert een fout in verkooprapporten en gebruikt lineage om de bron van de fout te vinden in een ETL-proces, waardoor ze het probleem binnen uren oplossen in plaats van dagen.
Migratieproject
Tijdens een cloudmigratie gebruikt een organisatie data lineage om te bepalen welke systemen en rapporten worden beïnvloed door de migratie van specifieke databronnen.
Tools voor Data Lineage
Verschillende tools kunnen helpen bij het implementeren van data lineage:
Open Source
- Apache Atlas
- Amundsen
- DataHub
- OpenMetadata
Commercieel
- Collibra
- Informatica
- Alation
- Talend
Cloud Native
- Azure Purview
- AWS Glue Data Catalog
- Google Data Catalog
Implementatiestappen voor Data Lineage
Veelgestelde Vragen
Wat is het verschil tussen data lineage en data provenance?
Data lineage focust op de technische stroom van data tussen systemen, terwijl data provenance zich richt op de oorsprong en geschiedenis van data, inclusief wie het heeft aangemaakt en gewijzigd.
Hoe onderhoud je data lineage bij frequente systeemwijzigingen?
Automatiseer zoveel mogelijk via metadata harvesting, integreer lineage in CI/CD pipelines en stel governance processen in voor handmatige updates wanneer nodig.
Is data lineage alleen relevant voor grote organisaties?
Nee, ook kleinere organisaties profiteren van data lineage, vooral wanneer ze groeien, compliance vereisten hebben of complexe dataprocessen ontwikkelen.